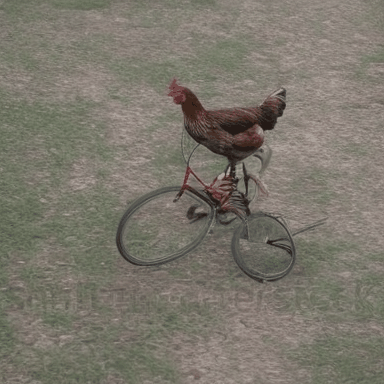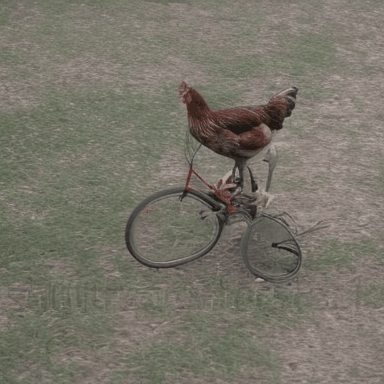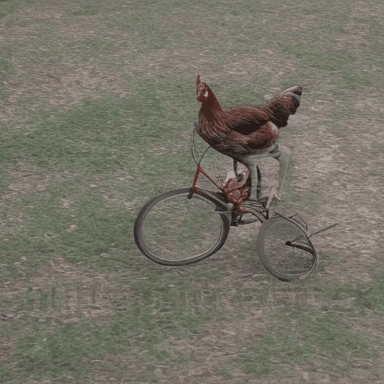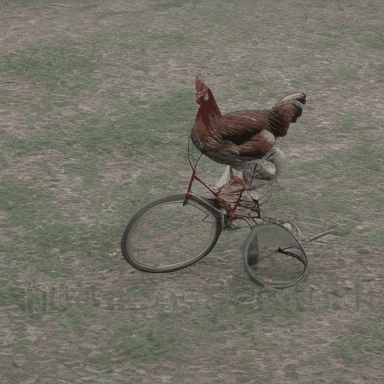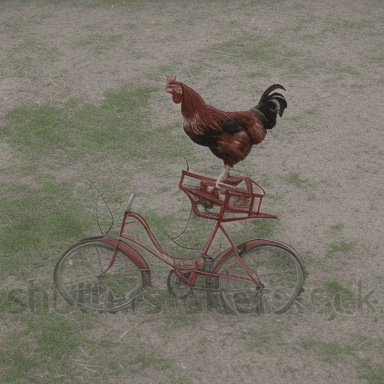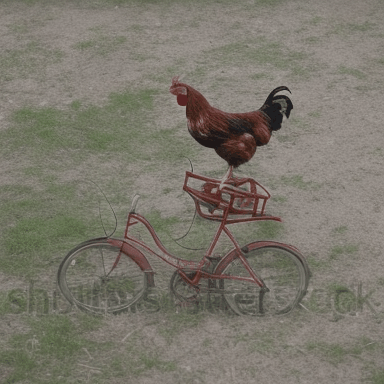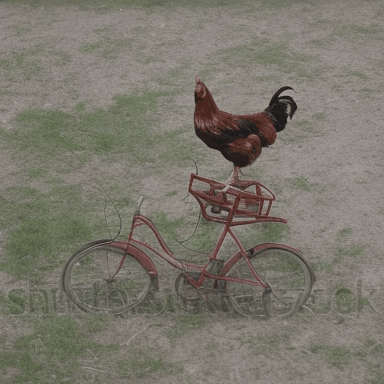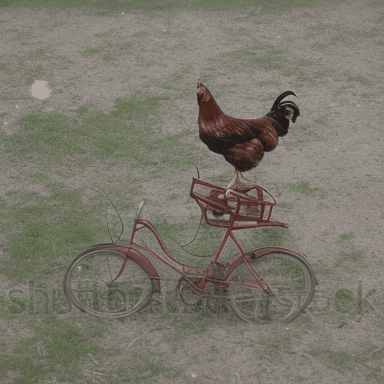We compare VADER against its base model ModelScope and prior alignment approaches, including DDPO and DiffusionDPO, using the aesthetics reward, for in-distribution prompts.









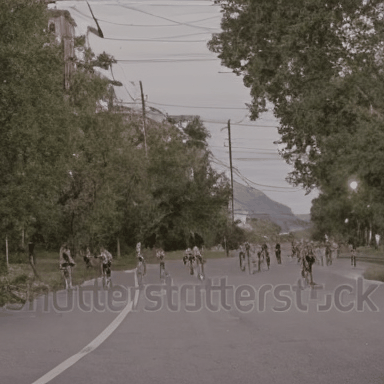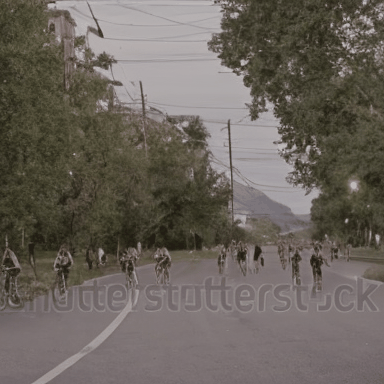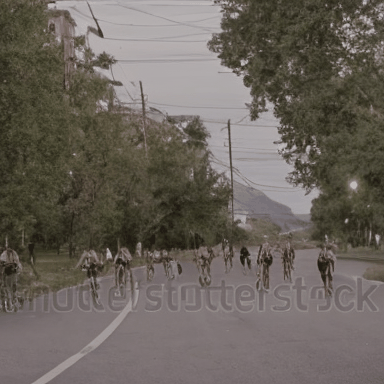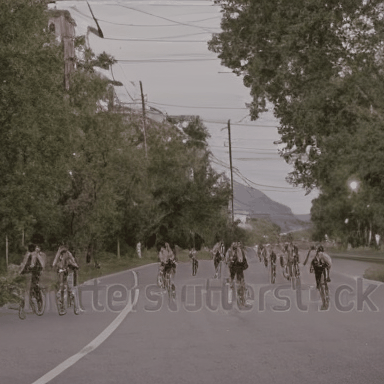
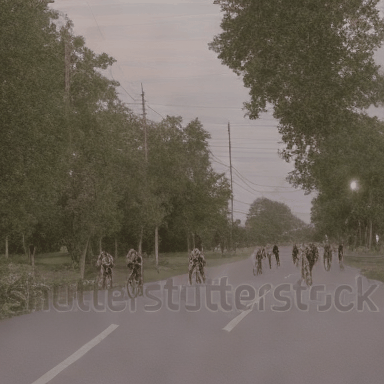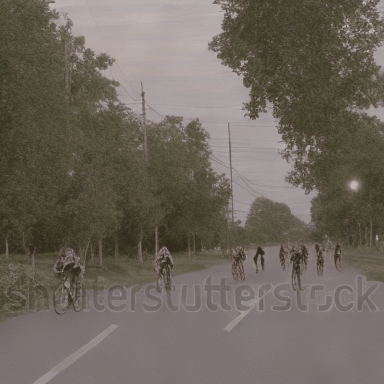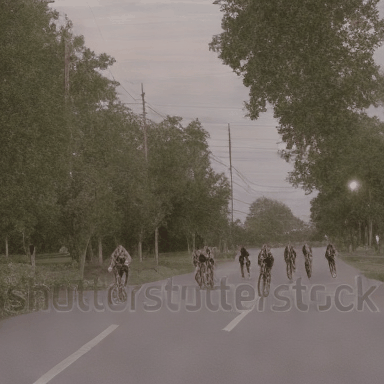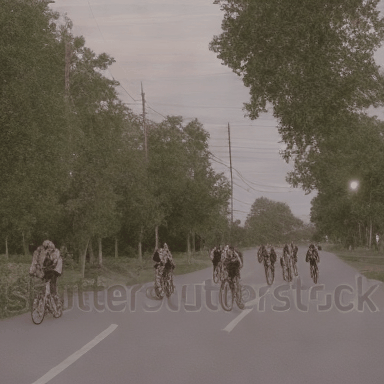
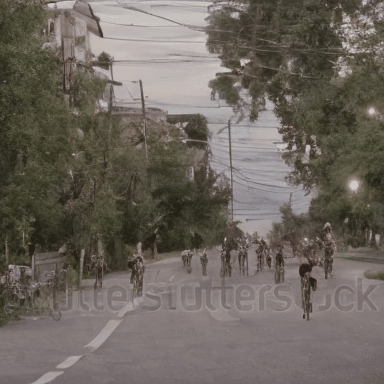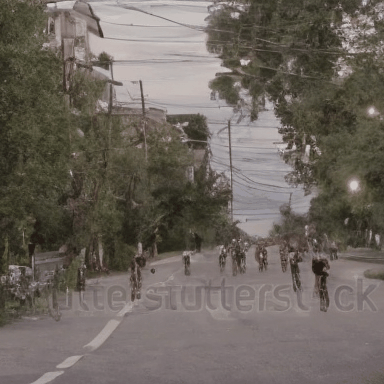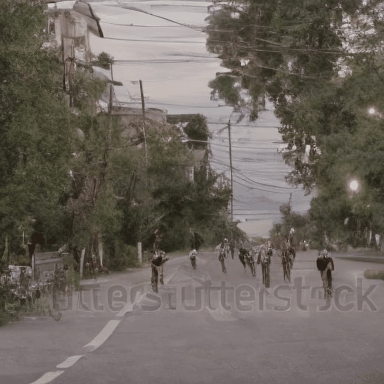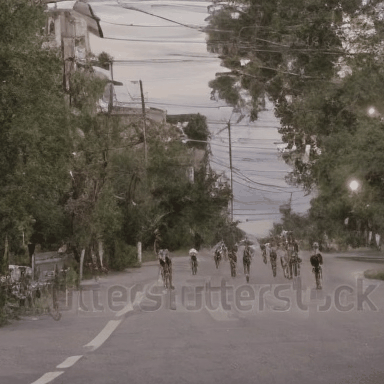
We compare VADER against its base model ModelScope and prior alignment approaches, including DDPO and DiffusionDPO, using the HPS reward, for in-distribution prompts.












We compare VADER against its base model ModelScope and prior alignment approaches, including DDPO and DiffusionDPO, using the aesthetics reward, for OOD prompts.

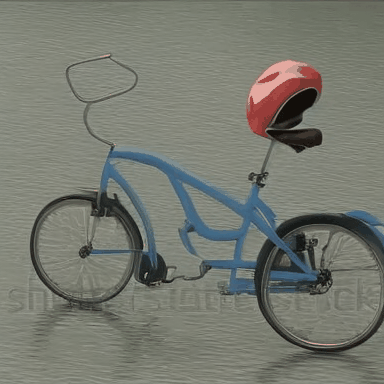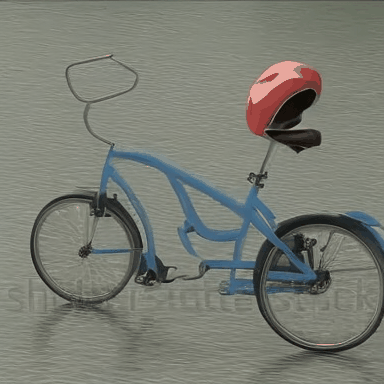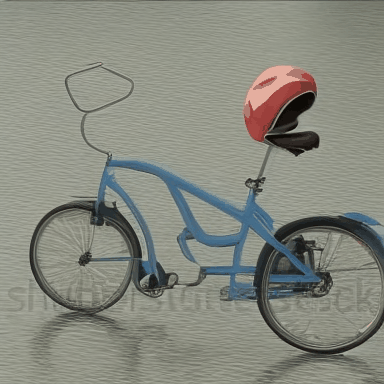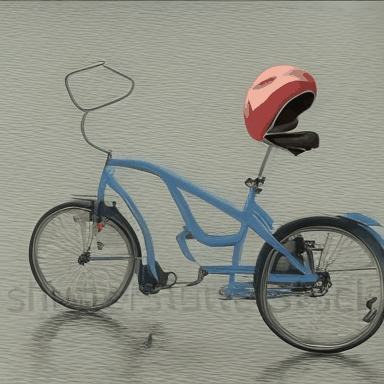

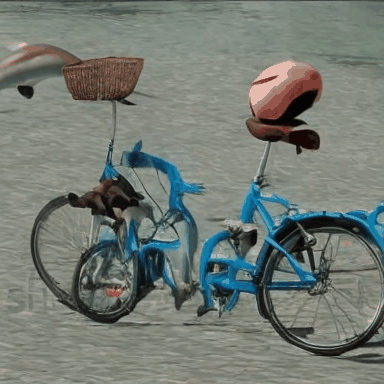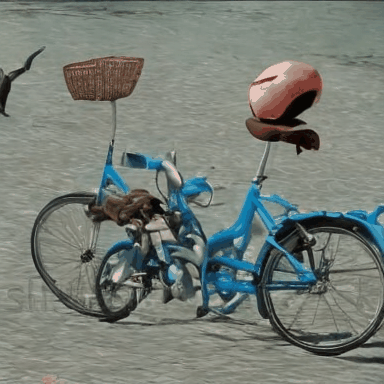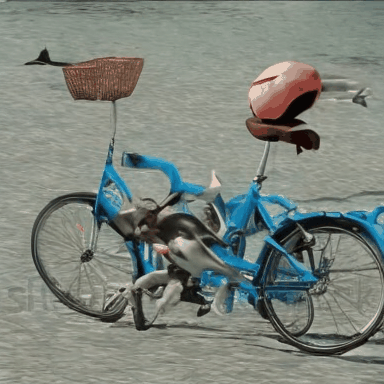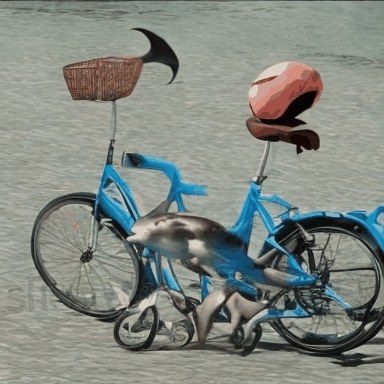







We compare VADER against its base model ModelScope and prior alignment approaches, including DDPO and DiffusionDPO, using the HPS reward, for OOD prompts.